- DONALD
- WŁAŚCICIEL TIKTOKA CHWALI SIĘ, ŻE STWORZYŁ MODEL SZTUCZNEJ INTELIGENCJI, KTÓRY ROBI IDEALNE DEEPFAKE
Właściciel TikToka chwali się, że stworzył model sztucznej inteligencji, który robi idealne deepfake
07.02.2025, 14:00

fot. X @TheAIColony
ByteDance
, właściciel TikToka, poinformował, że wprowadził
model sztucznej inteligencji
, który cieszy się szerokim zainteresowaniem ze względu na jego
zdolność do przekształcania zdjęć i krótkich filmików w realistyczne filmy
, zwane deepfake'ami.
Model
OmniHuman-1
może tworzyć realne filmy z ludźmi mówiącymi, śpiewającymi i poruszającymi się z jakością znacznie przewyższającą dotychczasowo tworzone nagrania. Korzysta z technologii Diffusion Transformer, dzięki czemu jest w stanie dokładnie przewidywać ruchy człowieka. AI od twórców TikToka używa obrazu referencyjnego i sygnałów ruchu.
Do wygenerowania wideo deepfake wystarczy jej tak naprawdę tylko jedno zdjęcie
.
OmniHuman-1 nie jest jeszcze dostępne dla użytkowników. Na razie opublikowano w sieci nagrania, na których widać efekty pracy AI od ByteDance. Viralem stało się
23-sekundowe wideo z Albertem Einsteinem
, wygłaszającym przemówienie. Eksperci zachwycają się jego jakością. Kyle Wiggers z TechCrunch nagrania stworzone ze pomocą OmniHuman-1 określił mianem "szokująco dobrych" i "
być może najbardziej realistycznych deepfake'ów w historii
".
Model AI od ByteDance tym samym może konkurować z modelem Sora od OpenAI, który również rozwija technologie generowania wideo na podstawie tekstu i dźwięku.

Hej, przypominamy tylko:
1. Szanujemy nawet ostrą dyskusję i wolność słowa, ale nie agresję. Przemocowe treści będą usuwane.
2. W komentarzach można swobodnie używać embedów z mediów społecznościowych.
3. Polecamy założenie konta, dzięki temu możesz zobaczyć wszystkie swoje dyskusje w jednym miejscu i dodać coś (👉 Sortownia), co trafi na stronę główną.
4. Jeżeli chcesz Donalda bez reklam, dołącz do naszych patronów: https://patronite.pl/donaldpl

Źródła:
2. https://www.youtube.com/watch?v=fY0KB516m-Ehttps://www.youtube.com/watch?v=fY0KB516m-E
Pokaż więcej (10)



NAJLEPSZE KOMENTARZE TYGODNIA
![Sondaż: połowa Polaków chciałaby Wielkiego Piątku jako dnia wolnego od pracy]()
![Niemcy pokazały wyniki eksperymentu z dawaniem 1200 euro "za nic"]()
![Rubio: Trump ma inne problemy niż wojna Rosja-Ukraina i USA mogą przestać zabiegać o pokój]()
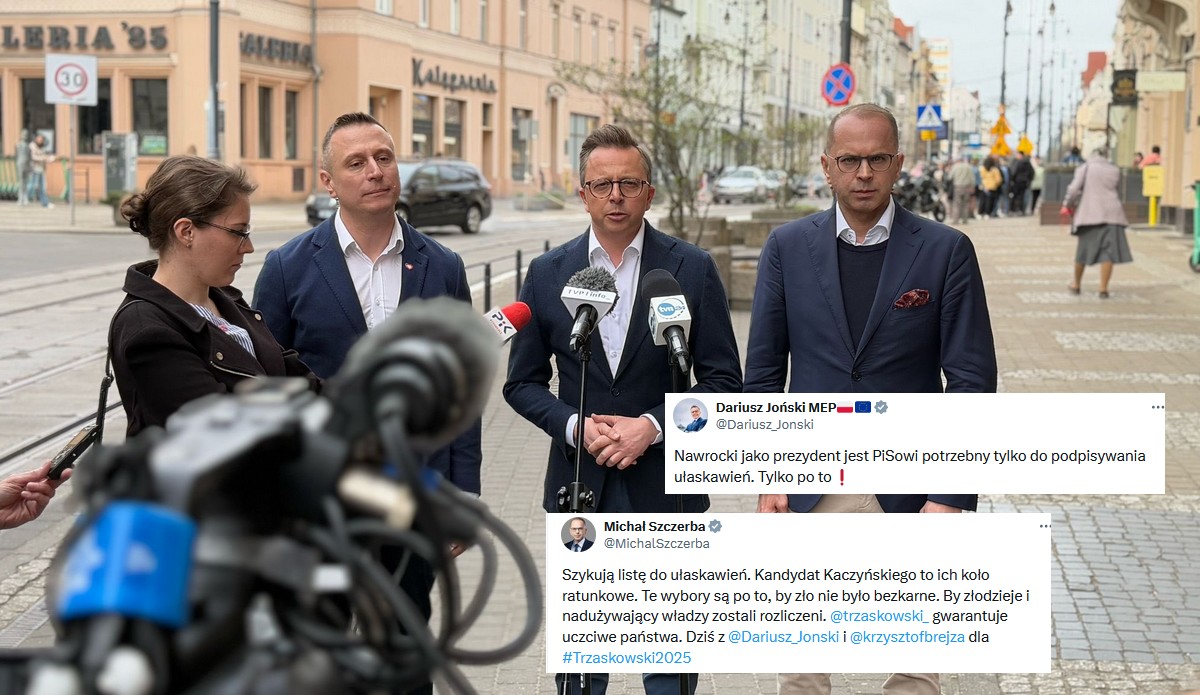
![Żołnierka ochrzaniła przełożonego i pochwaliła się znajomościami, okazało się, że będą konsekwencje]() Więcej popularnych
Więcej popularnych
Popularne dzisiaj
Sondaż: połowa Polaków chciałaby Wielkiego Piątku jako dnia wolnego od pracy

20
Odsetek zwolenników tego rozwiązania spada. Zobacz więcej »
Niemcy pokazały wyniki eksperymentu z dawaniem 1200 euro "za nic"

34
Okazało się, że bezwarunkowy dochód podstawowy nie doprowadził do spadku aktywności zawodowej. Zobacz więcej »
Rubio: Trump ma inne problemy niż wojna Rosja-Ukraina i USA mogą przestać zabiegać o pokój

51
"To nie jest nasza wojna. Nie zaczęliśmy jej". Zobacz więcej »
Żołnierka ochrzaniła przełożonego i pochwaliła się znajomościami, okazało się, że będą konsekwencje
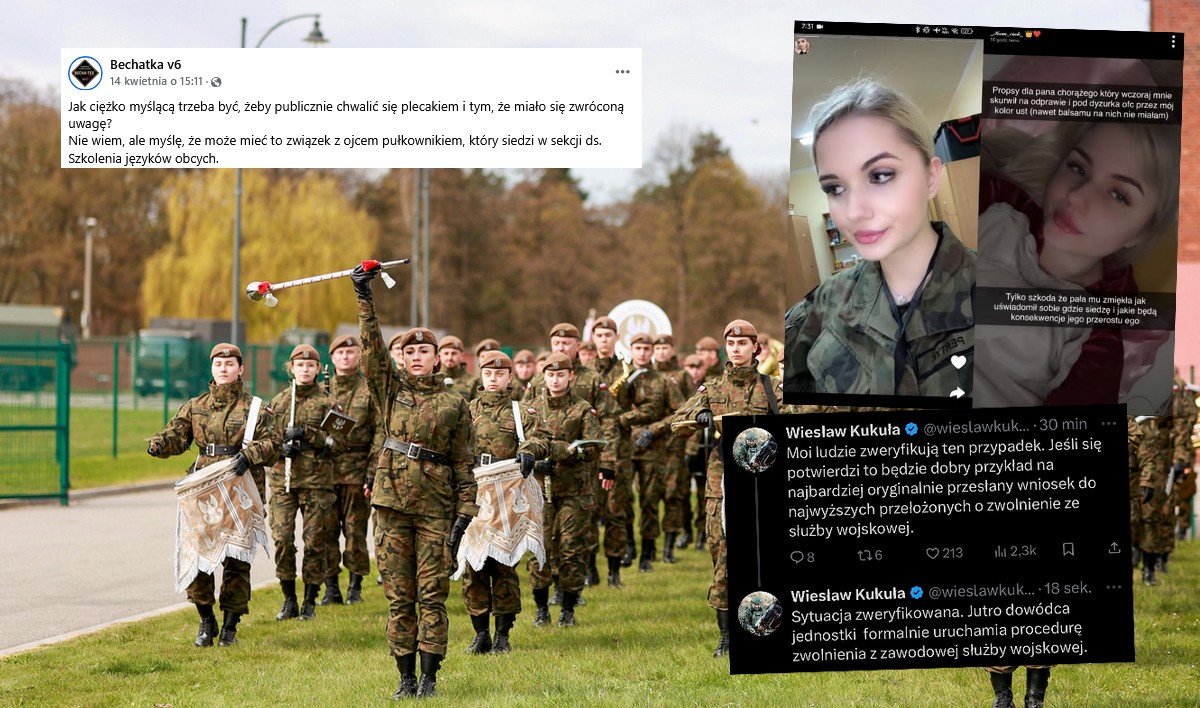
46
"Sytuacja zweryfikowana. Jutro dowódca jednostki formalnie uruchamia procedurę zwolnienia z zawodowej służby wojskowej". Zobacz więcej »